8.12 OpenStack之主机调度¶

一般情况下,一个 OpenStack 中,会部署有许多个计算节点。当我们创建一个虚拟机时,OpenStack 如何决定要将我们的虚拟机创建在哪里呢?这就是 openstack-nova-scheduler 要做的事。
顾名思义,它是对集群内的所有计算节点的资源情况进行比较。主要分为两个过程:
1、根据计算节点的资源情况,过滤掉不符合创建虚拟机的规格的计算节点;
2、根据既定的规则,对过滤器筛选出的合格的计算节点,进行权重计算,选出最优节点。
经过以上两个过程后,nova-scheduler 会将选到的主机返回给 nova-conductor,这时候 nova-conductor 才会去调用 nova-compute 去进行真正的创建过程。
8.12.1 过滤器和称重器¶
接下来,我会从源码的角度来分析一下这个过程。
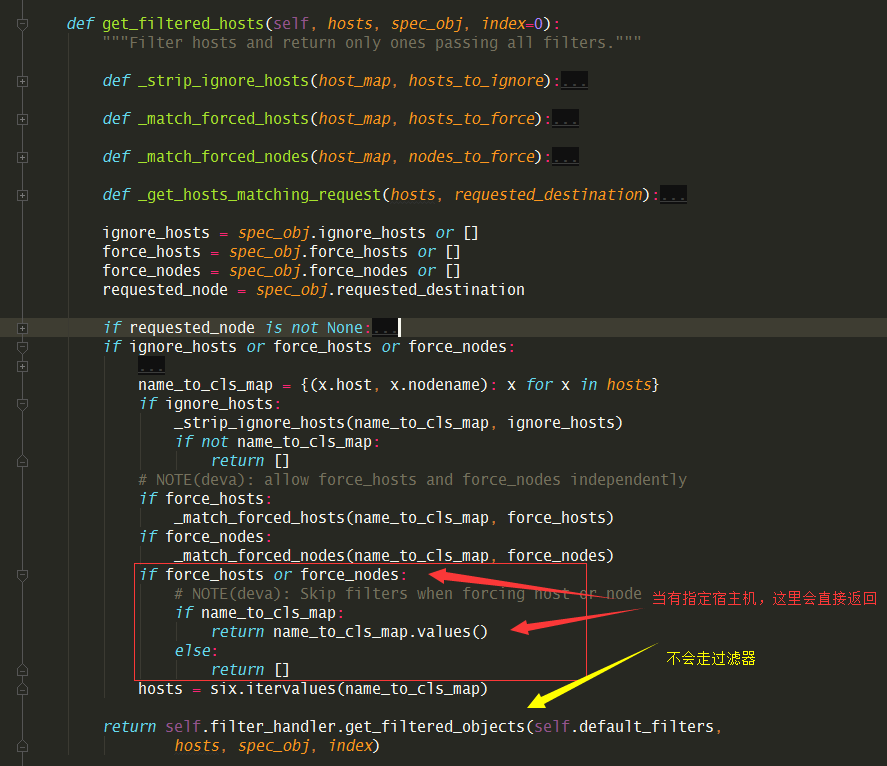
从源代码中看,最开始是 nova-conductor (nova/conductor/manager.py)在给 nova-compute 发创建请求前,会先让 nova-scheduler 选出一台资源充足的计算节点。
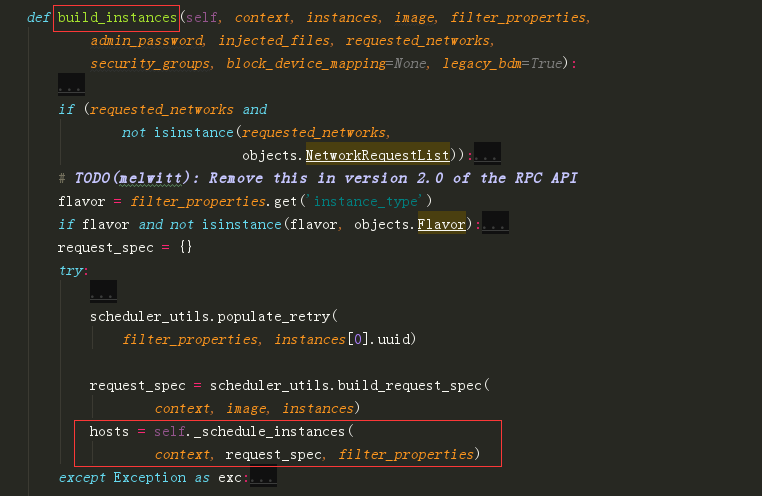
nova-scheduler 的调度主要由两部分组成(nova/scheduler/filter_scheduler.py:FilterScheduler._schedule())
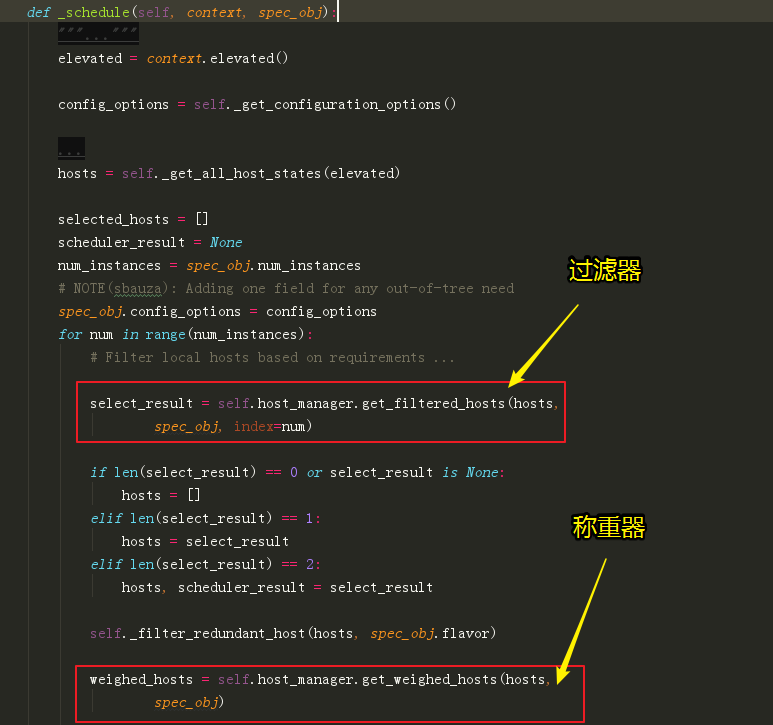
过滤器:filter,将不满足条件(硬性条件,比如内存,cpu,磁盘,pci设备等)的计算节点,直接过滤掉。意义:从过滤器出来的那些计算节点,理论上都可以创建虚拟机。
称重器:weigher,对满足硬性条件的众多主机按照一定的规则进行权重配比。意义:经过称重器计算,选出你更希望在哪台节点上创建虚拟机。
不管是过滤器,还是称重器,它们都需要两个参数
hosts:多个 host_state 的集合,包含有当前可用的计算节点信息(资源,ip等)。其中单个元素是 HostState (nova/scheduler/host_manager.py)类的实例。如果你想添加其他原来没有的信息,比如 compute 的 id,可以在
_update_from_compute_node函数中添加。它会从compute_nodes 表中取得你想要的信息。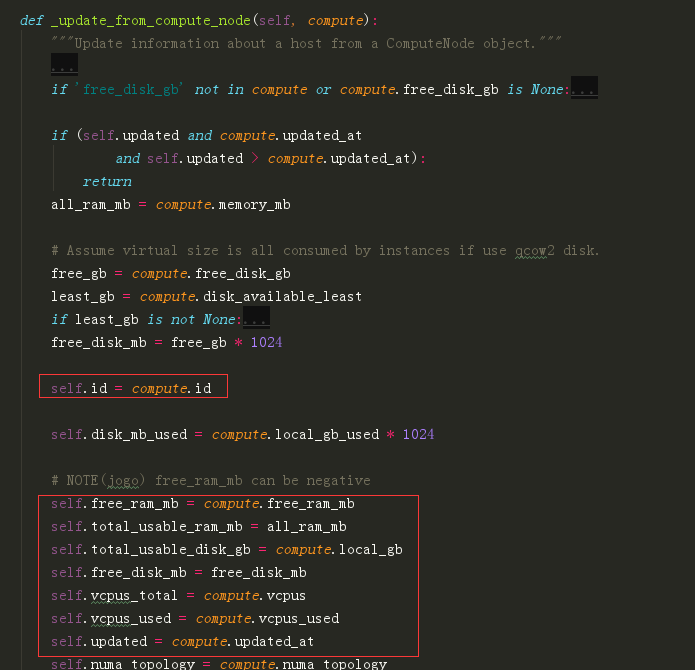
spec_obj:你所要请求创建的虚拟机信息(模板,镜像等)。它是从 objects.RequestSpec.from_primitives 中取得的
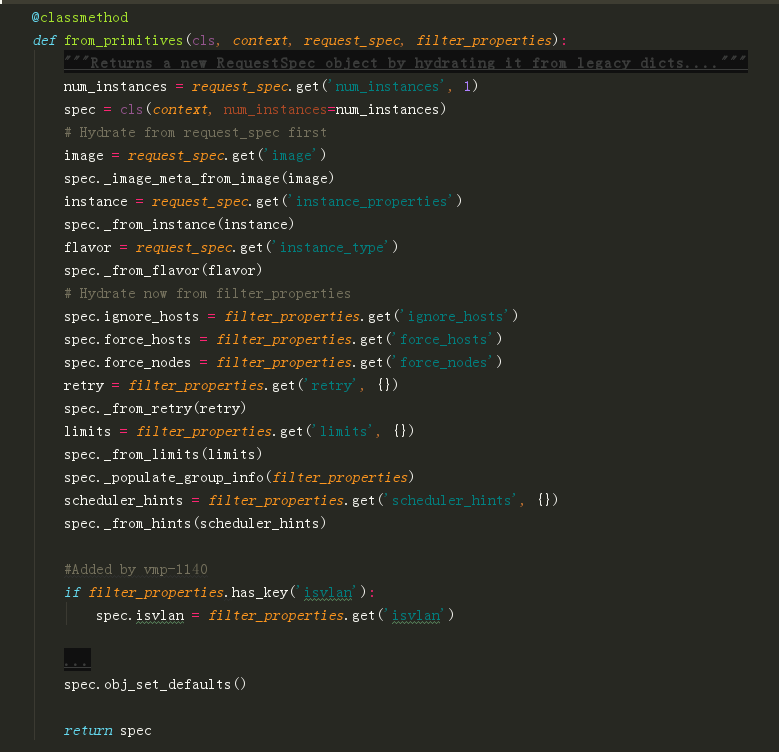
过滤器,它的代码如下:
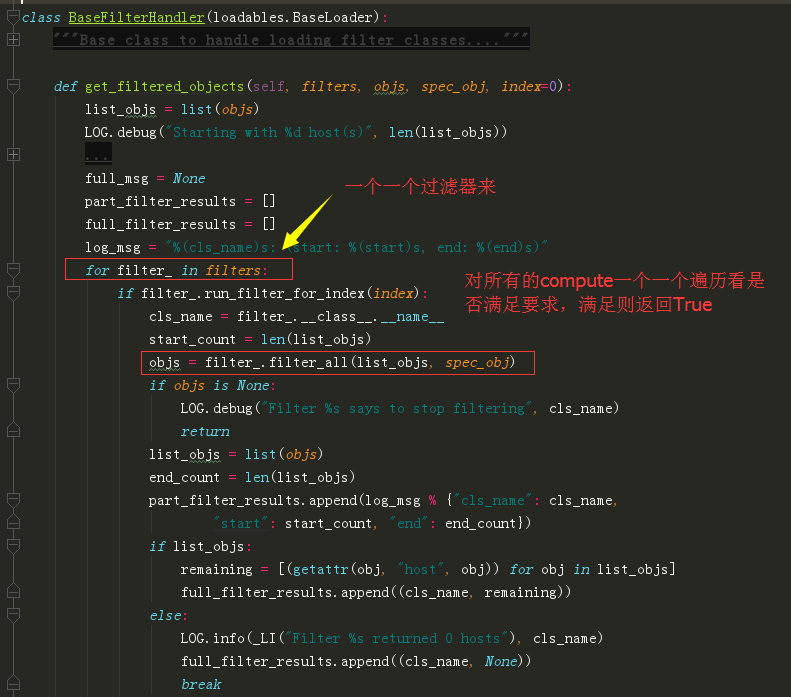
称重器,它的规则主要看这段代码。

我在代码中,加了几段日志。从左到右,三个不同颜色的内容分别为,原始权值,配重系数(越高说明越占比越大,越影响最终结果),经过 nomalize 后的权值(只有 0 和 1)。
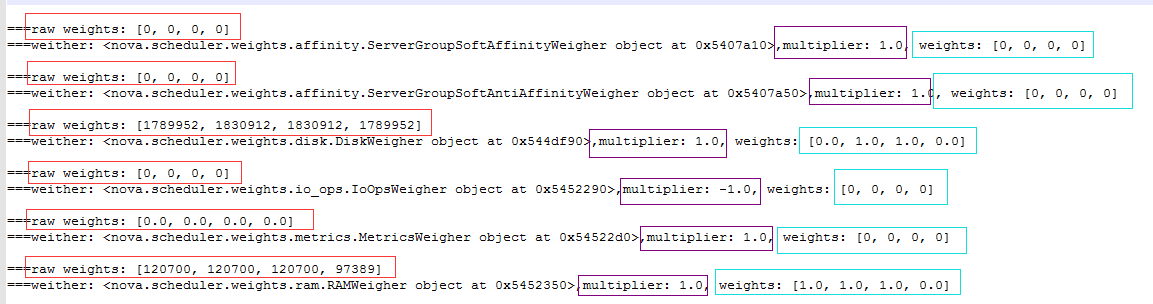
那最终的权值如何计算呢?
先计算每一个称重器后的权重: weights * multipier
最后按不同的compute 将权重相加起来。
nova-scheduler 选择到主机后,在日志中会打印三条DEBUG信息,可以据此查看
LOG.debug("Filtered %(hosts)s", {'hosts': hosts})
LOG.debug("Weighed %(hosts)s", {'hosts': weighed_hosts})
LOG.debug("Selected host: %(host)s", {'host': chosen_host})