8.5 OpenStack 源码剖析与改造¶

8.5.1 虚拟机是如何创建出来的?¶
生成xml,准备网络(plug_vif)创建domain 是在
_create_domain_and_network 这个函数中
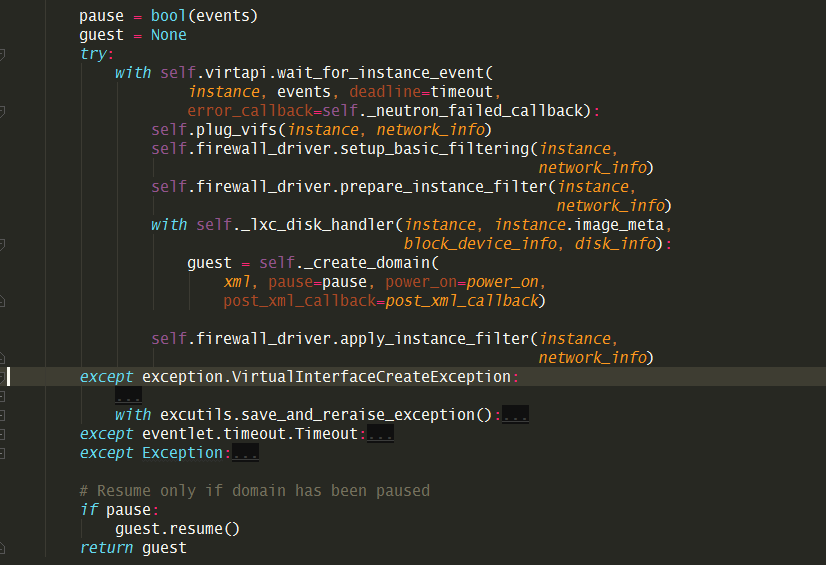
这个函数,只有在 spawn 、_hard_reboot 和 finish_migration
才会执行。
通过libvirt的接口创建虚拟机
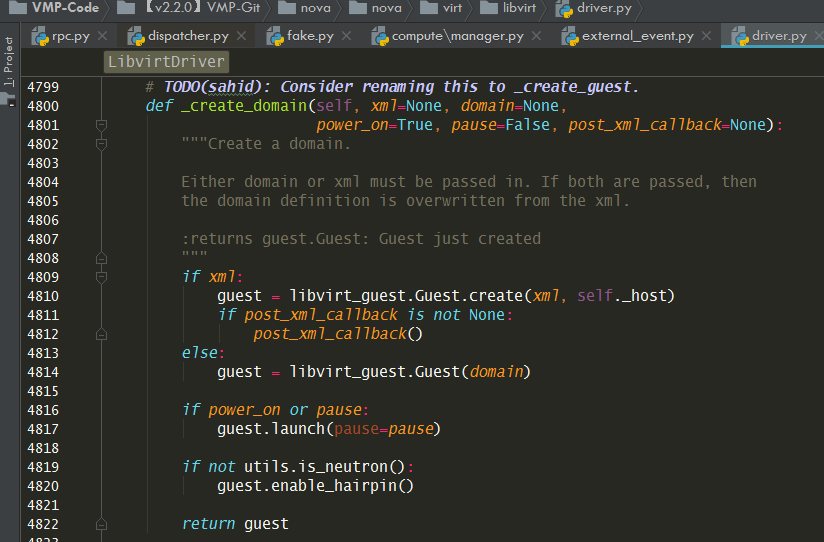
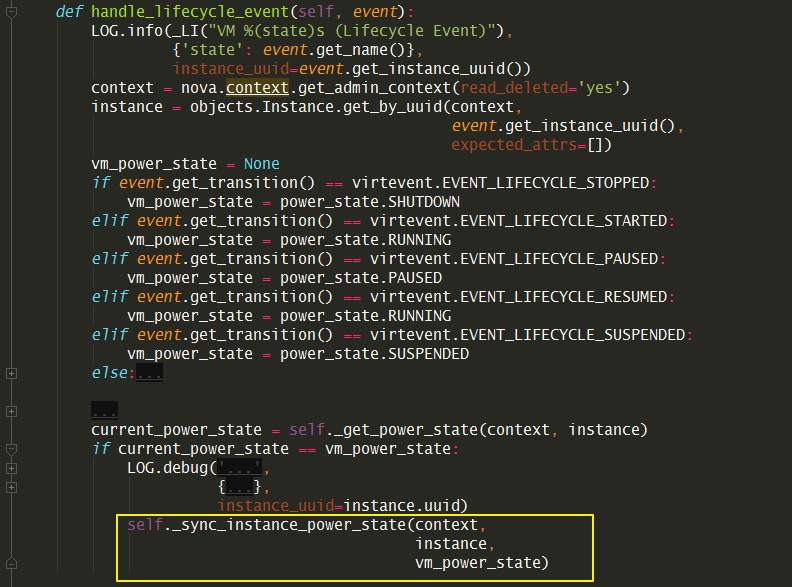
8.5.2 同步虚机电源状态¶
虚拟机在 hypervisor 的真实状态和 OpenStack 数据库管理的状态可能有出入。
比如客户可能在虚拟机内部自己执行 shutdown -h now
,那么虚机就进入合理正常的关机状态了,可这个状态并不是由 OpenStack
触发的,所以OpenStack 需要定时任务去检查真实的电源状态,并实时更新。
这个定时任务是利用 eventlet 这个库去做的
class ComputeManager(manager.Manager):
def __init__(self, compute_driver=None, *args, **kwargs):
# CONF.sync_power_state_pool_size 默认是 1000
self._sync_power_pool = eventlet.GreenPool(
size=CONF.sync_power_state_pool_size)
self._syncs_in_progress = {}
默认是 600s,就是10分钟同步一次数据库的状态。
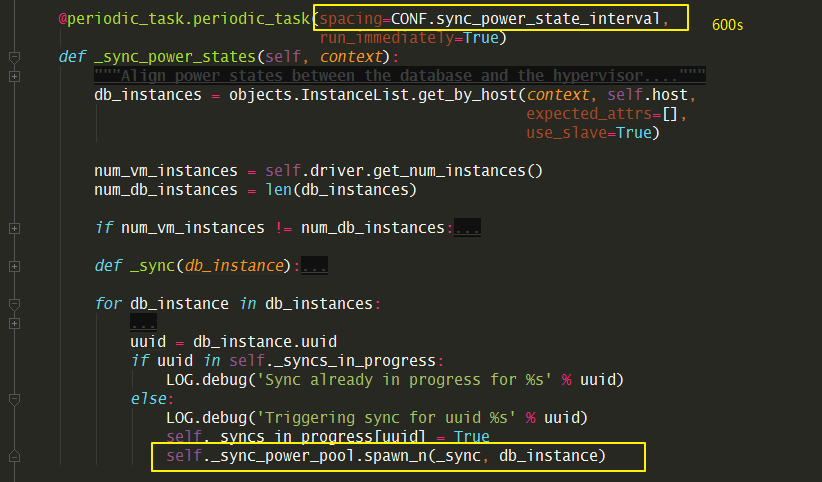
具体的函数是在这个 _sync_instance_power_state
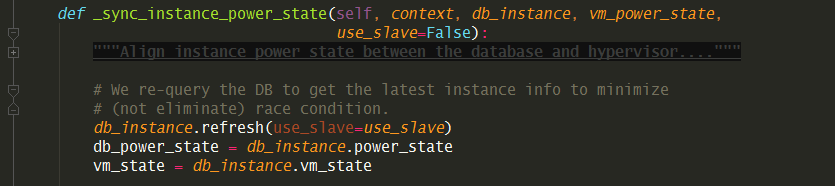
注意这个函数只有两个地方会调用
一个是上面 时间间隔 10分钟 的定时任务,时间明显有点长。
还有一个是由 libvirt 触发的lifecycle event
事件,这个只要在虚拟机在hypervisor层发生状态变动时,就会调用。
8.5.3 创建快照代码解读?¶
8.5.4 虚拟机状态¶
vm_state 描述虚拟机当前的稳定状态,其值可以在
nova/compute/vm_states.py看到
ACTIVE
BUILDING
PAUSED
SUSPENDED
STOPPED
RESCUED
RESIZED
SOFT_DELETED
DELETED
ERROR
SHELVED
power_state
描述的是从hypervisor传过来的状态,其值可在nova/compute/power_state.py
NOSTATE
RUNNING
PAUSED
SHUTDOWN
CRASHED
SUSPENDED
task_state 描述的是中间任务状态,
spawning
networking
scheduling
block_device_mapping
在创建虚拟机时,会有几次会产生虚拟机状态(vm_state和task_state)的上报(到ceilomet er)。
nova
提供了一个配置项:notify_on_state_change,本意是想,如果配置vm_state就只在vm_state
第一次,在manager.py:2050的函数
_do_build_and_run_instance里,看instance.save()
8.5.5 快照镜像如何实现?¶
nova-api 的入口如下
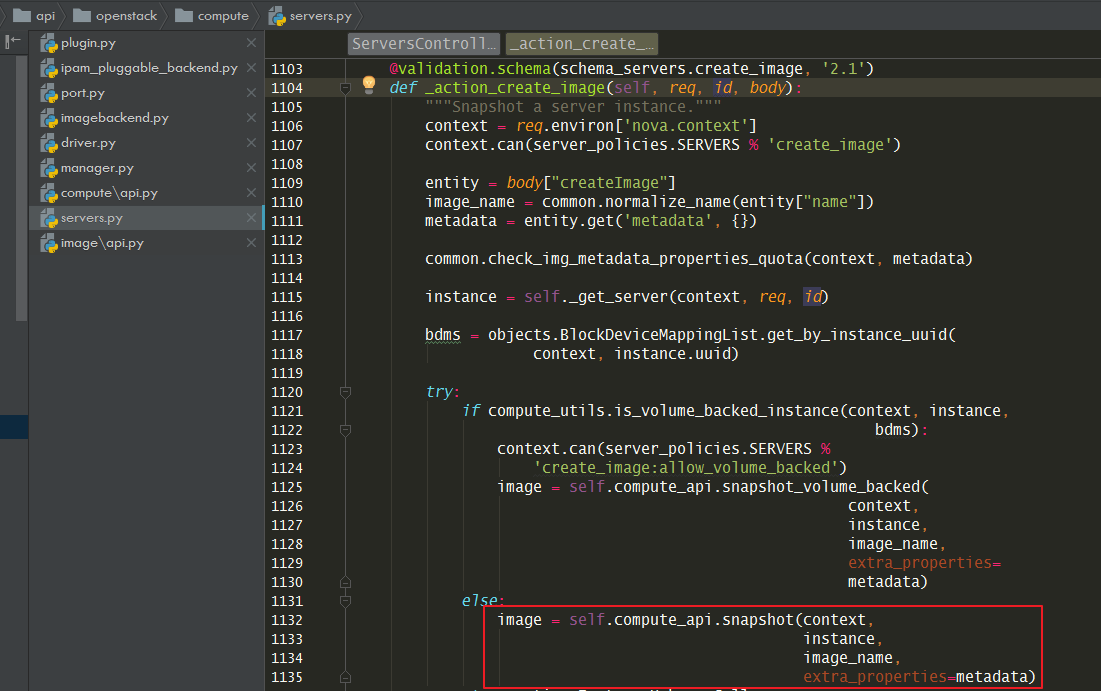
接着会调用 nova/compute/api.py
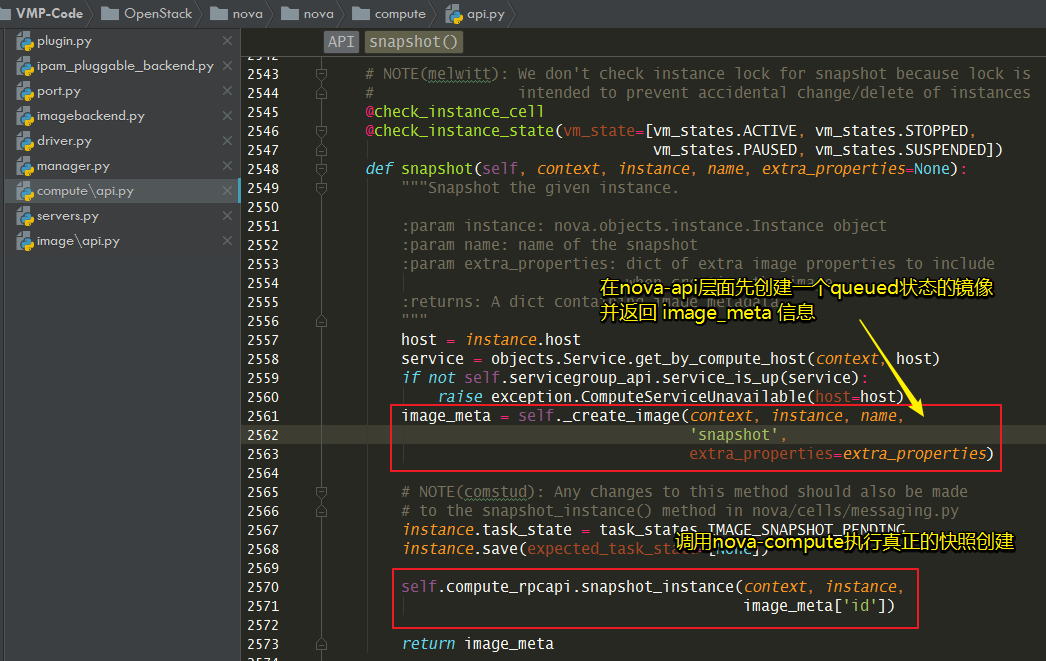
在nova-compute 层面:nova/compute/manager.py:_snapshot_instance()
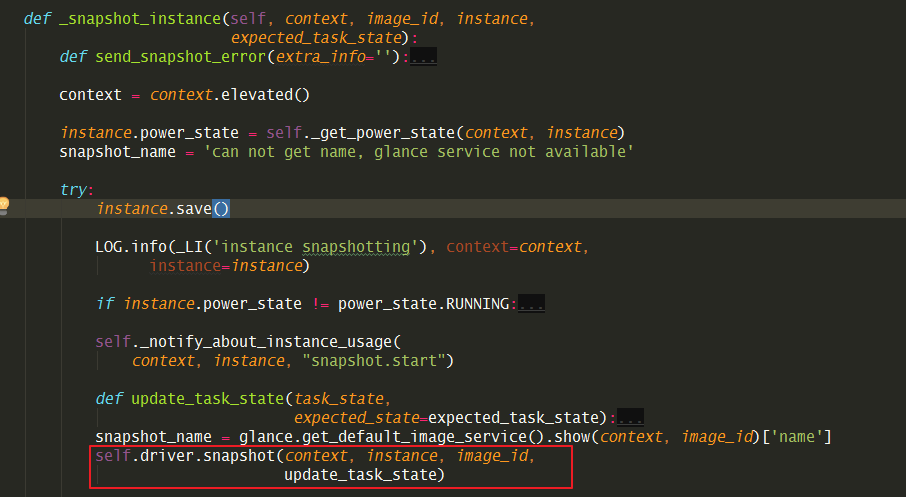
接下来会调用 nova/virt/libvirt/driver.py:snapshot()
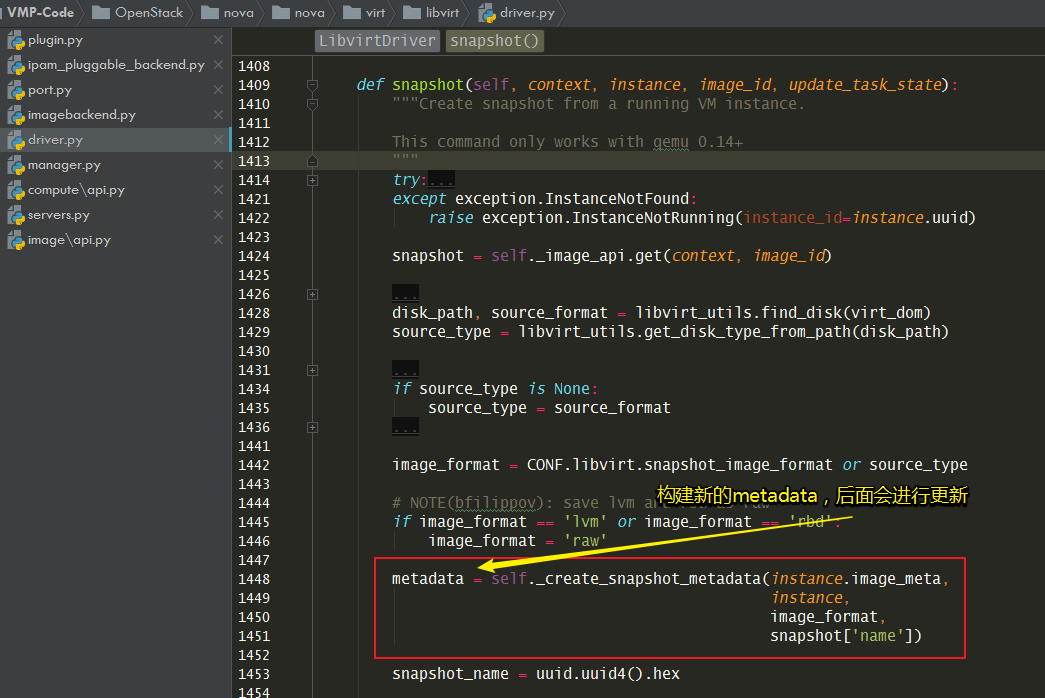
先获取imagebackend的类型,然后找到对应的backend
disk_path, source_format = libvirt_utils.find_disk(virt_dom)
source_type = libvirt_utils.get_disk_type_from_path(disk_path)
...
snapshot_backend = self.image_backend.snapshot(instance,
disk_path,
image_type=source_type)
接下来,会调用对应的imagebackend的snapshot_extract 方法。
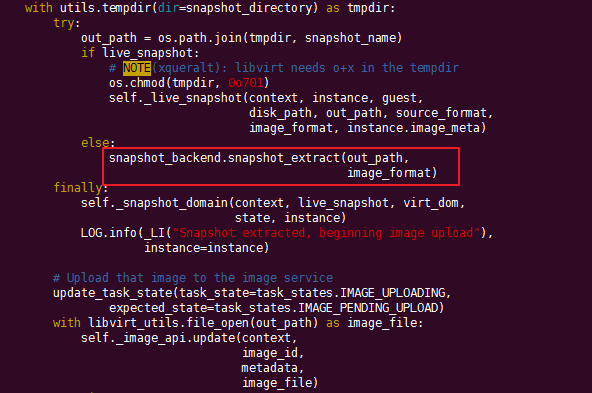
snapshot_extract
方法最终会调用nova/virt/images.py:_convert_image()
,可以看出其实底层调用的是 qemu-img 提供的convert 接口。

如果是qcow2的backend,不是调用这边,而是调用
nova/virt/libvirt/utils.py:extract_snapshot()

1551944122412¶
如果要查询镜像压缩的时间,可以在compute上执行这个命令
grep -E "Start executing commands|End executing commands" /var/log/nova/nova-compute.log
以上,就是整个镜像创建的过程。
独立磁盘模式的暂时不支持,原因分析如下。
在libvirt_utils.get_disk_type_from_path
里没有相应的修改,导致返回的是lvm。
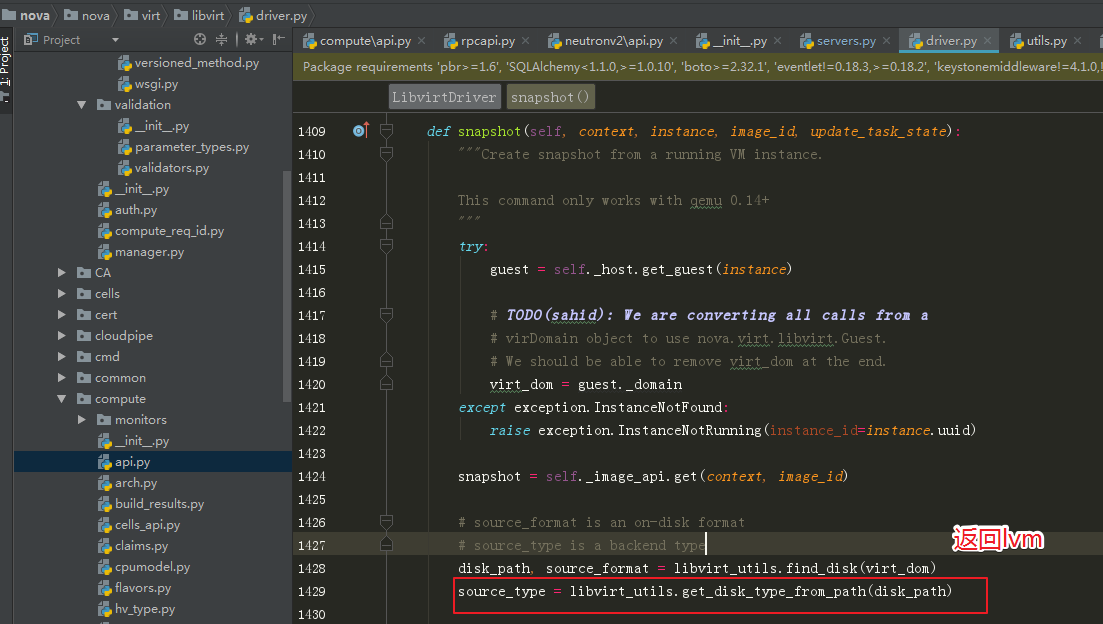
后面的imagebackend也相应的变成 lvm的
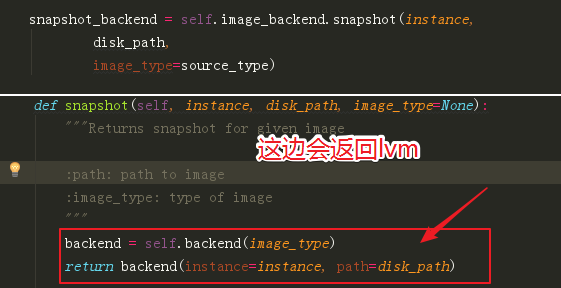
然后会进入 lvm这个backend的init函数。由于path 是/dev/sdb
并不是一个lv,所以这边会报错。

1551940635806¶
下次修改方法:一个是最开始获取source_type时判断为isolate,一个是后面
isolate的extract_snapshot 也要和lvm一样实现一下。
8.5.6 宿主机资源采集上报¶
compute的资源上报,是在
nova/compute/resource_tracker.py:_init_compute_node 里。
从宿主机上获取数据:update_available_resource 函数下的
resources = self.driver.get_available_resource(self.nodename)
其调用的函数是virt/libvirt/driver.py 里的
get_available_resource 函数
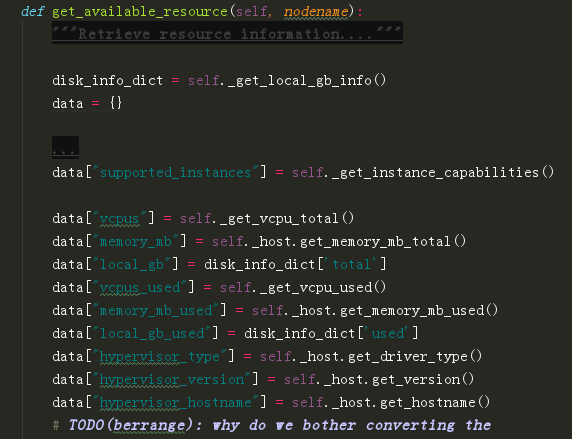
从数据库获取旧数据
self.compute_node = self._get_compute_node(context)
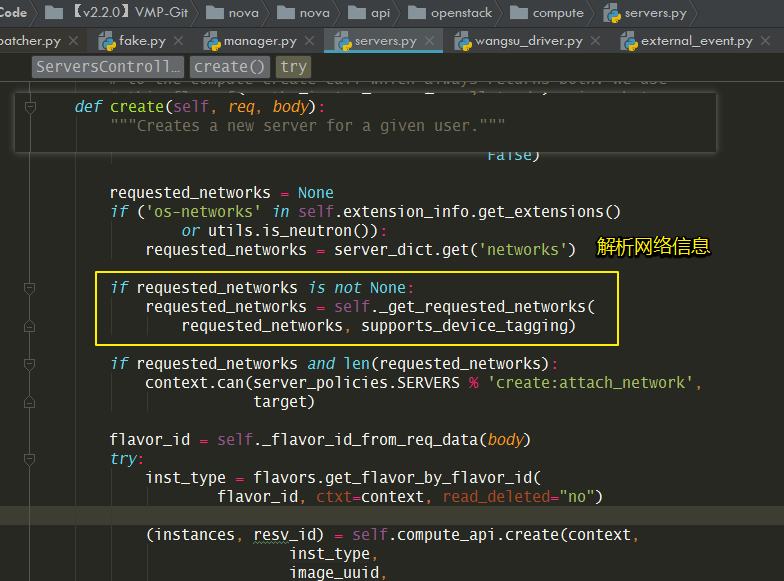
8.5.7 虚拟机的ip是如何分配的?¶
这一节主要讲两个点:
Port 是如何创建的?
network_info 是如何组装的?
虚拟机配置网络可以cloudinit从 ConfigDrive
里取得网络信息,然后配置。而这里的网络信息是怎么来的呢,这就是本节要讲的内容,它就是
network_info 信息,它的最终去向是 ConfigDrive。
在创建虚拟机时,需要的资源有很多,而网络就是其中一种(network_info),其他的还有
block_device_info 。
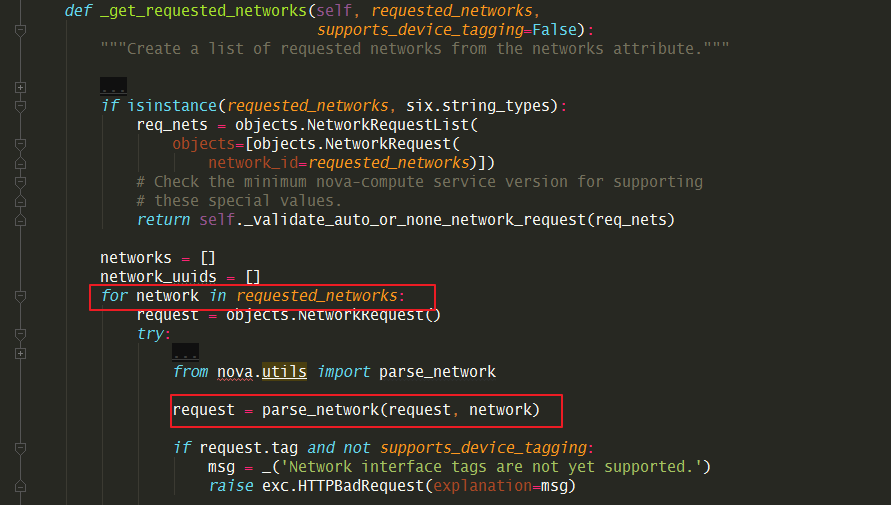
当你看完本节后,你会发现,network_info 其实是创建完 port 后,根据port的信息组装成一个对象。
虚拟机创建资源的代码是在 nova/compute/manager.py 里的
_build_resource() 里
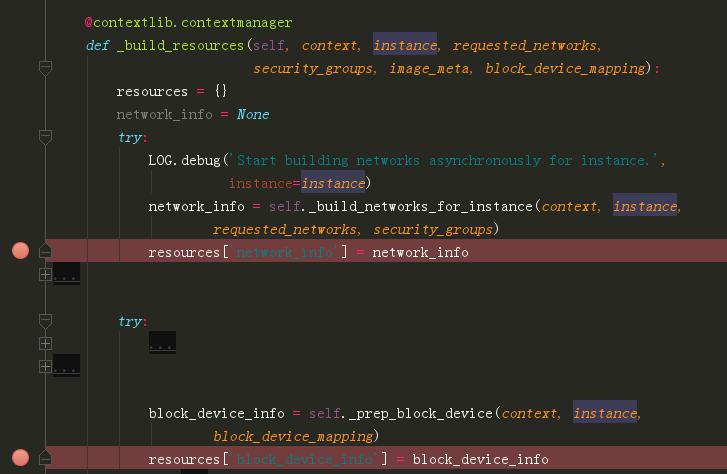
这里只讲一下 network_info,其他的我都忽略了。

在这个函数_allocate_network() ,主要做如下两件事。
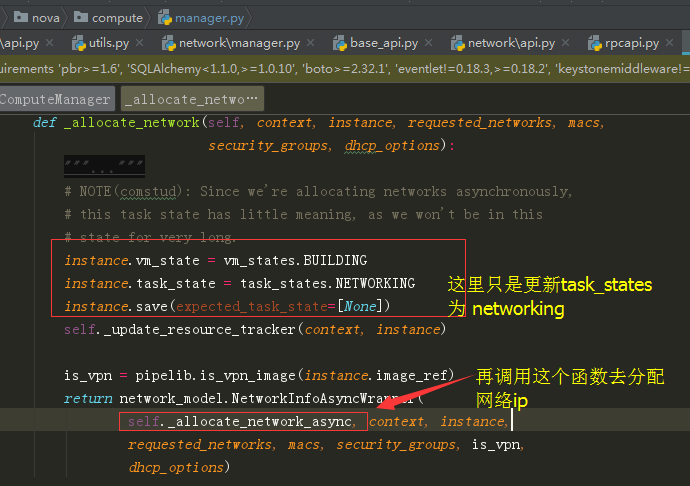
继续进入这个函数,如果不指定重试次数,默认是一次。
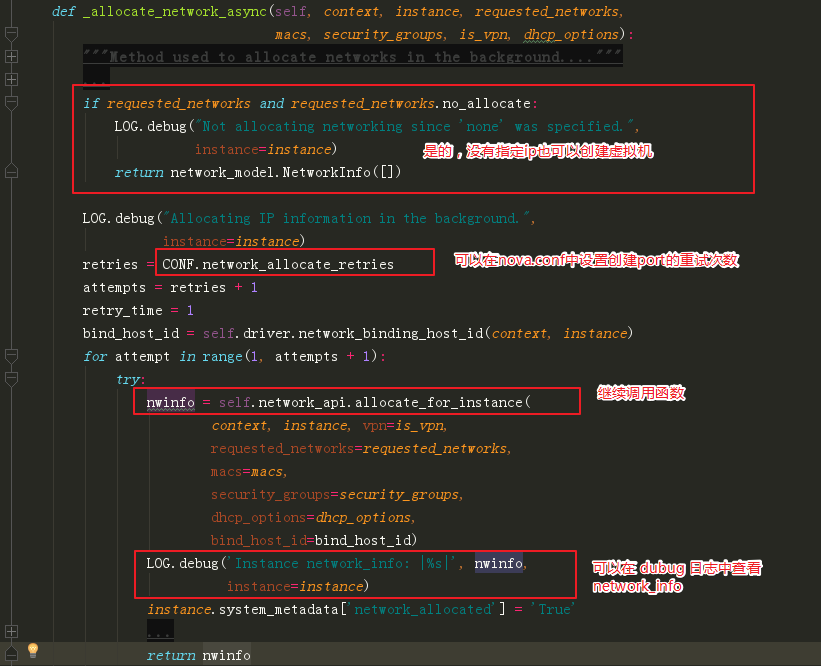
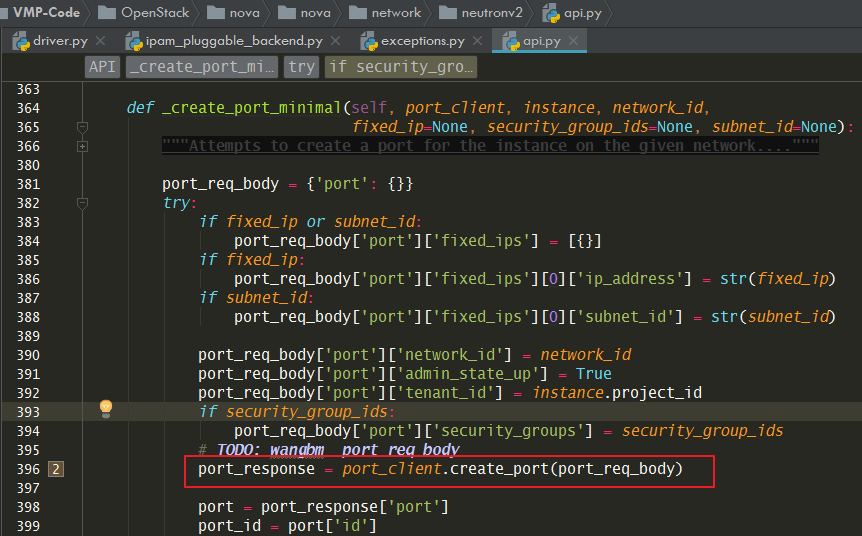
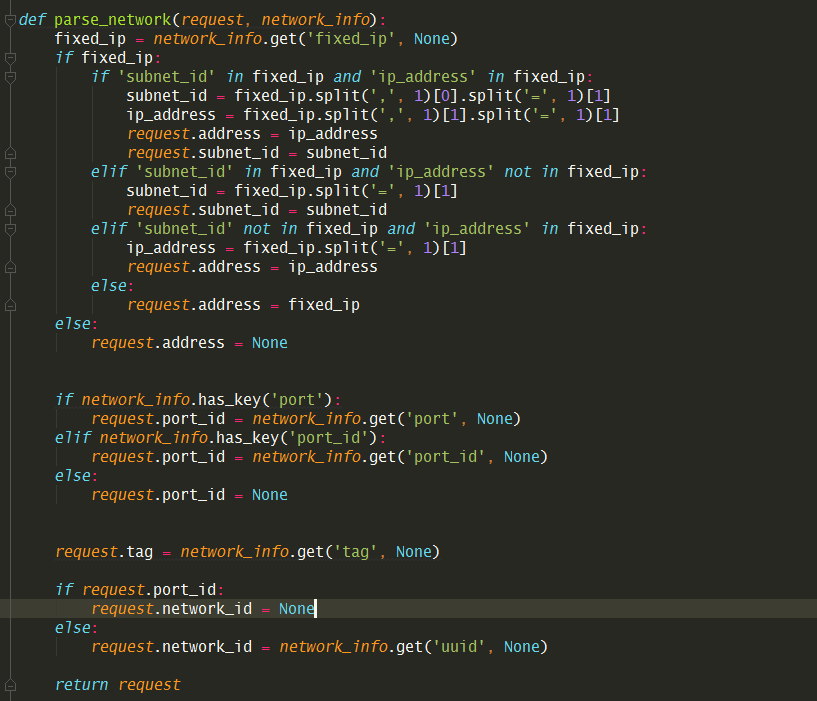
接下来就是调用我们非常熟悉的 _create_port_minimal 函数去创建port
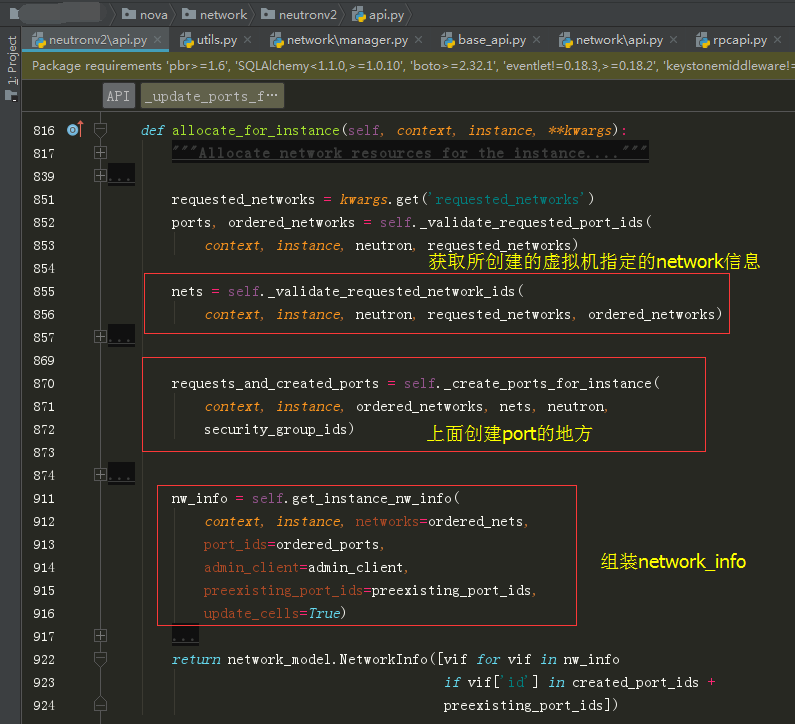
如果你全局搜索,你会发现,在 network/rpc.py 下也有这个函数,这个是通过 nova interface-attach 为虚拟机添加网卡,从 nova-api 那边发起的 rpc 请求,才会走到这里
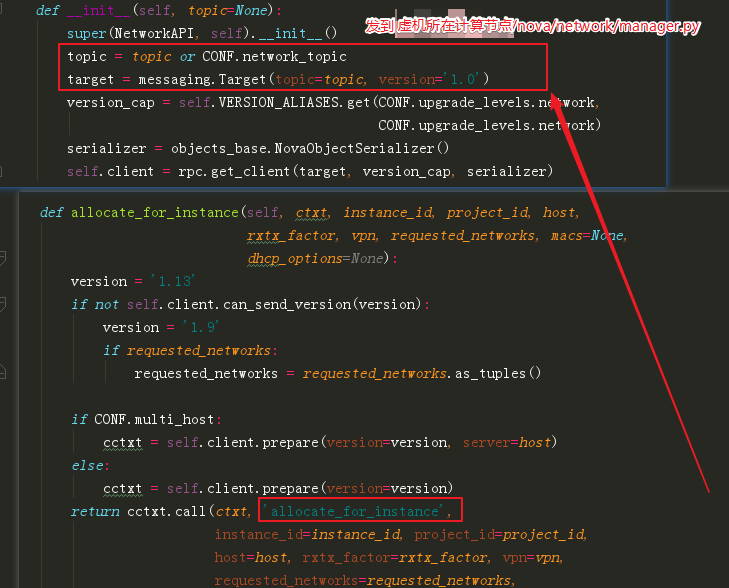
上面创建完port了,后面最后一个函数,我已经标出来了,开始组装获取 network_info 对象。
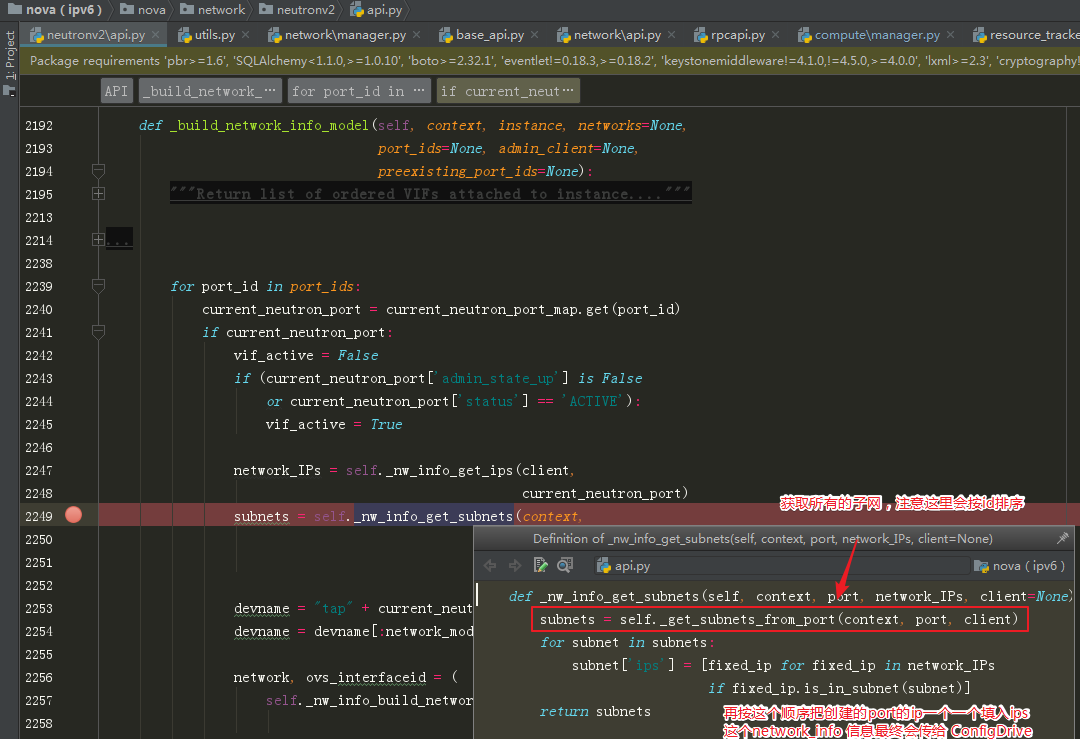
上面是创建虚拟机时,创建 network_info 对象的过程。
如果虚拟机已存在,那么如果获取呢,可以用这个函数
network_info = compute_utils.get_nw_info_for_instance(instance)

8.5.9 指定ip时检查allocation_pools¶
在原生的 neutron 中,当你指定 ip(172.20.22.64) 来创建虚拟机时,假如子网的 allocation_pools 是 172.20.20.100 - 172.20.20.200 ,那 neutron 是不会去检查你指定的ip是否在 allocation_pools 中的。
先来看看,port 是如何创建的
若要解决这个问题,可以参考原生代码中,在为子网添加allocation_pool时,验证是否合法的的逻辑,代码如下

然后在 neutron\neutron\db\ipam_pluggable_backend.py
文件中添加我们检查 ip是否在 allocation_pools 中的逻辑代码。
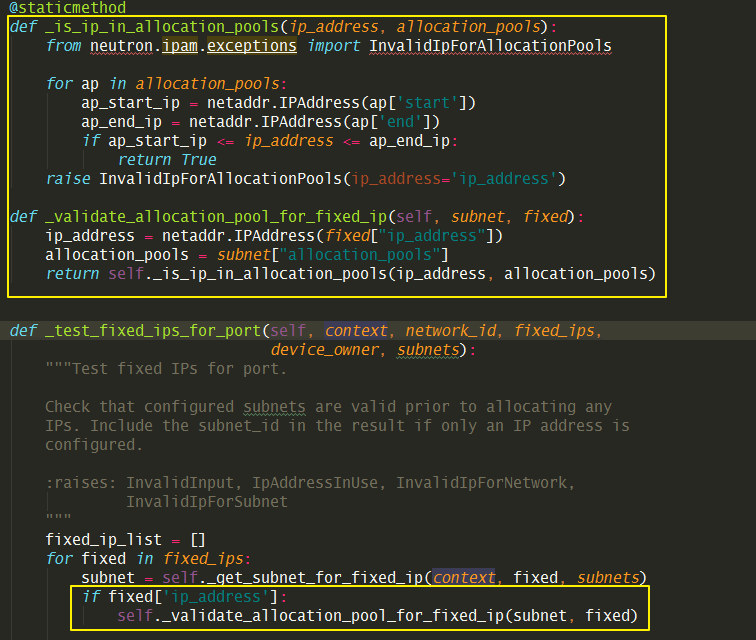
# 代码如下:方便复制
@staticmethod
def _is_ip_in_allocation_pools(ip_address, allocation_pools):
from neutron.ipam.exceptions import InvalidIpForAllocationPools
for ap in allocation_pools:
ap_start_ip = netaddr.IPAddress(ap['start'])
ap_end_ip = netaddr.IPAddress(ap['end'])
if ap_start_ip <= ip_address <= ap_end_ip:
return True
raise InvalidIpForAllocationPools(ip_address='ip_address')
def _validate_allocation_pool_for_fixed_ip(self, subnet, fixed):
ip_address = netaddr.IPAddress(fixed["ip_address"])
allocation_pools = subnet["allocation_pools"]
return self._is_ip_in_allocation_pools(ip_address, allocation_pools)
然后还要定义一个异常类型

若指定的ip在allocation pool 里,则正常创建,若不在allocation 里,就会在 nova-compute 日志中报错。
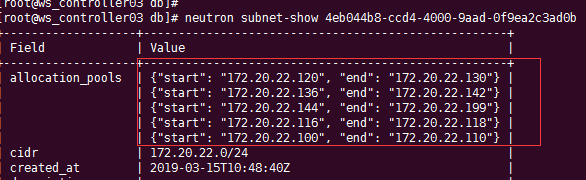
可以发现我们的ip 172.20.22.64 并不在子网的allocation pool,理所当然在nova的日志中可以看到相应的报错。
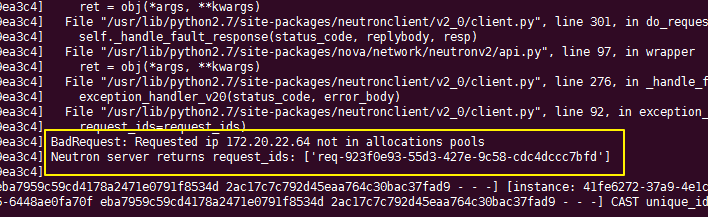
8.5.10 attach port时ip占用提示¶
当你调用 os-interface
(指定了ip)接口给一台虚拟机添加一张网卡时,若这个ip已经被使用。
nova-api 返回的结果令人无法理解:
[{"computeFault": {"message": "Unexpected API Error. Please report this at http://bugs.launchpad.net/nova/ and attach the Nova API log if possible.\n<class 'oslo_messaging.rpc.client.RemoteError'>", "code": 500}}].
究其原因,是 nova 在调用neutron的api 创建port时,如果ip已被占用,必须neutron会抛出 IpAddressAlreadyAllocated,而在 neutronclient 只有 IpAddressInUseClient 的异常,并不匹配,在neutronclient 端与neutron 对应的异常应该为 IpAddressAlreadyAllocatedClient 。
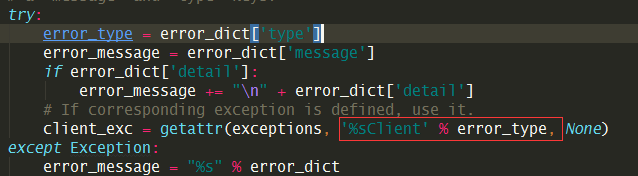
如何让nova-api能够返回具体的错误信息呢?
解决方法有两种,
一种是,在 neutronclient/common/exceptions.py 里添加 IpAddressAlreadyAllocatedClient 异常。
并且在nova 创建port的代码处,捕获这个异常
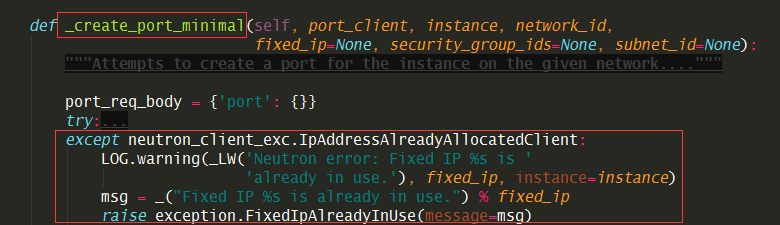
这种要改两个组件,而且要将neutronclient 的代码也管理起来,较为麻烦
一种是,只改neutron,在neutron/ipam/exceptions.py 添加一个与 neutronclient 相对应的异常。

然后修改 neutron/ipam/drivers/neutrondb_ipam/drivers.py 修改异常类型
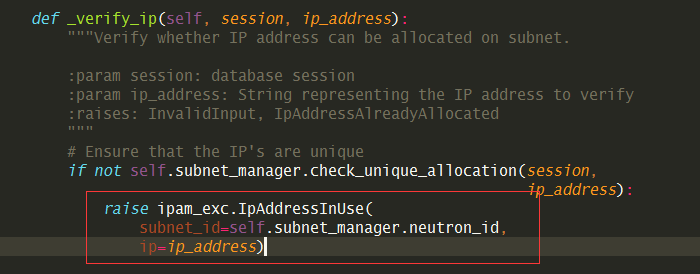
通过 postman 进行模拟,已经可以返回具体的信息
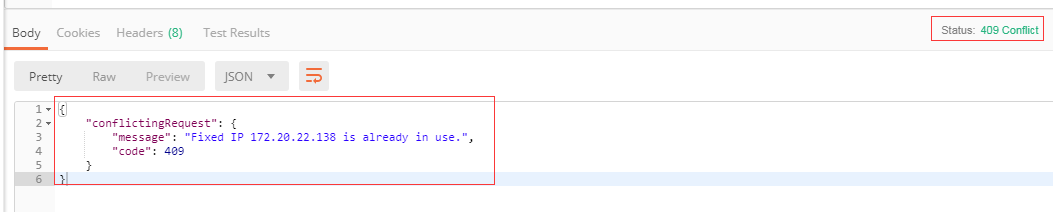
另附:neutron 是如何判断ip是否已经占用?代码如下
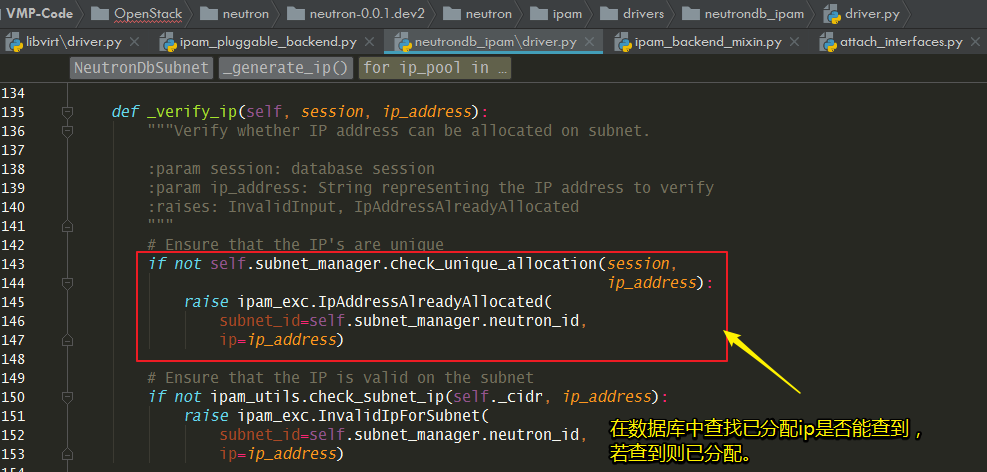
8.5.11 nova-compute 如何启动的?¶
从 /usr/bin/nova-compute 这个文件可以了解到nova-compute的入口是
nova.cmd.compute:main()

从这个入口进去,会开启一个 nova-compute 的服务。
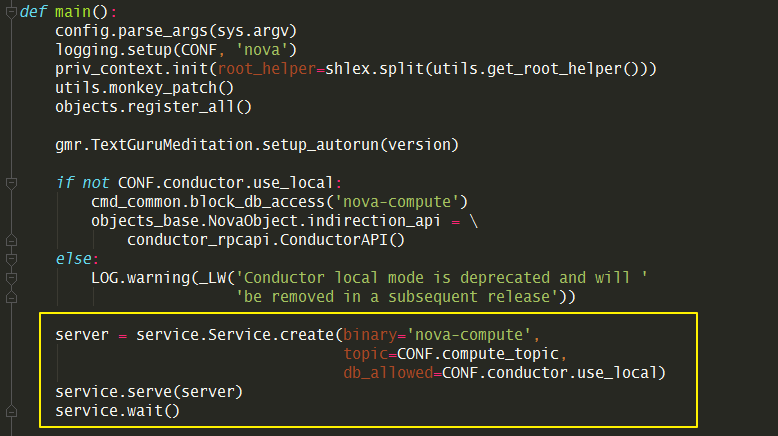
当调用 service.Service.create 时(create
是一个工厂函数),实际是返回实例化的 service.Service 对象。当没有传入
manager 时,就会以binary 里的为准。比如binary
是nova-compute,那manager_cls 就是
compute_manager,对应的manager 导入路径,会从配置里读取。

8.5.12 往 spec_obj 里添加对象¶
在 nova-scheduler 里的 过滤器里,有俩非常重要的对象。
host_state:包含每台 host 的所有信息
spec_obj:包含创建虚拟机请求的所有信息

有时候,spec_obj 里并没有我们想要的信息(比如虚拟机的 metadata),这时候,我们就要手动添加。
这里我以 metadata 为例,来讲一下这个添加过程。
首先第一点要清楚的是,spec_obj 其实是 RequestSpec 对象:nova/objects/request_spec.py,所以下面的修改都是在这个文件里进行。
要往这个对象加属性,第一步是要定义这个字段。
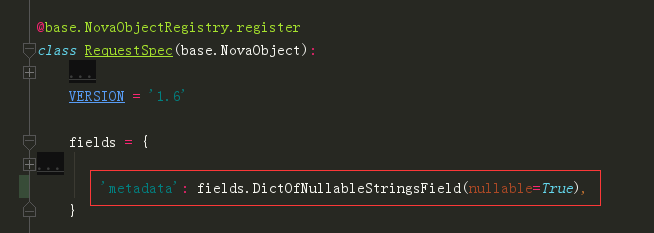
往 instance_fields 追加属性名,完了后,这个属性会出现在
request_spec['instance_properties'] 里
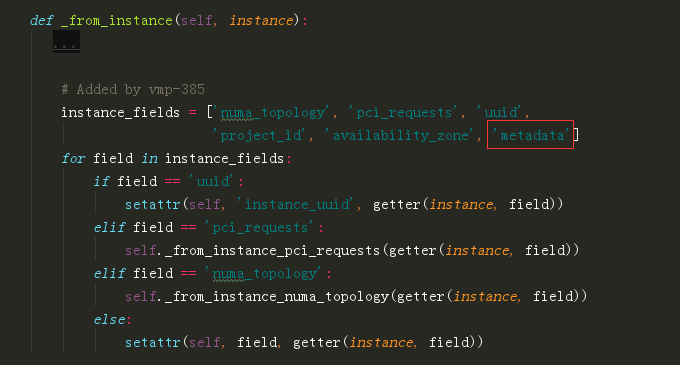
最后在 from_primitives 这个函数里,把这个新属性赋值给 request_spec
对象。
spec.metadata = request_spec['instance_properties'].get('metadata', {})
8.5.14 HTTP 状态码¶
在 标准库 WebOB 中
Exception
HTTPException
HTTPOk
* 200 - :class:`HTTPOk`
* 201 - :class:`HTTPCreated`
* 202 - :class:`HTTPAccepted`
* 203 - :class:`HTTPNonAuthoritativeInformation`
* 204 - :class:`HTTPNoContent`
* 205 - :class:`HTTPResetContent`
* 206 - :class:`HTTPPartialContent`
HTTPRedirection
* 300 - :class:`HTTPMultipleChoices`
* 301 - :class:`HTTPMovedPermanently`
* 302 - :class:`HTTPFound`
* 303 - :class:`HTTPSeeOther`
* 304 - :class:`HTTPNotModified`
* 305 - :class:`HTTPUseProxy`
* 307 - :class:`HTTPTemporaryRedirect`
* 308 - :class:`HTTPPermanentRedirect`
HTTPError
HTTPClientError
* 400 - :class:`HTTPBadRequest`
* 401 - :class:`HTTPUnauthorized`
* 402 - :class:`HTTPPaymentRequired`
* 403 - :class:`HTTPForbidden`
* 404 - :class:`HTTPNotFound`
* 405 - :class:`HTTPMethodNotAllowed`
* 406 - :class:`HTTPNotAcceptable`
* 407 - :class:`HTTPProxyAuthenticationRequired`
* 408 - :class:`HTTPRequestTimeout`
* 409 - :class:`HTTPConflict`
* 410 - :class:`HTTPGone`
* 411 - :class:`HTTPLengthRequired`
* 412 - :class:`HTTPPreconditionFailed`
* 413 - :class:`HTTPRequestEntityTooLarge`
* 414 - :class:`HTTPRequestURITooLong`
* 415 - :class:`HTTPUnsupportedMediaType`
* 416 - :class:`HTTPRequestRangeNotSatisfiable`
* 417 - :class:`HTTPExpectationFailed`
* 422 - :class:`HTTPUnprocessableEntity`
* 423 - :class:`HTTPLocked`
* 424 - :class:`HTTPFailedDependency`
* 428 - :class:`HTTPPreconditionRequired`
* 429 - :class:`HTTPTooManyRequests`
* 431 - :class:`HTTPRequestHeaderFieldsTooLarge`
* 451 - :class:`HTTPUnavailableForLegalReasons`
HTTPServerError
* 500 - :class:`HTTPInternalServerError`
* 501 - :class:`HTTPNotImplemented`
* 502 - :class:`HTTPBadGateway`
* 503 - :class:`HTTPServiceUnavailable`
* 504 - :class:`HTTPGatewayTimeout`
* 505 - :class:`HTTPVersionNotSupported`
* 511 - :class:`HTTPNetworkAuthenticationRequired`
8.5.15 不同存储方式xml¶
lvm
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' io='native'/>
<source dev='/dev/hdd-volumes/0fd65882-945e-4386-b2f2-5a36d62fefad_disk.eph0'/>
<target dev='vdb' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>
</disk>
qcow2
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2' cache='writeback'/>
<source file='/var/lib/nova/instances/12522ab8-703f-4528-beb0-5ae5767a0a42/disk/disk'/>
<target dev='vda' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>
</disk>
config(configdrive)
<disk type='file' device='cdrom'>
<driver name='qemu' type='raw' cache='writeback'/>
<source file='/var/lib/nova/instances/12522ab8-703f-4528-beb0-5ae5767a0a42/disk.config'/>
<target dev='hda' bus='ide'/>
<readonly/>
<address type='drive' controller='0' bus='0' target='0' unit='0'/>
</disk>
isolate
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' io='native'/>
<source dev='/dev/sdb'/>
<target dev='vdb' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>
</disk>
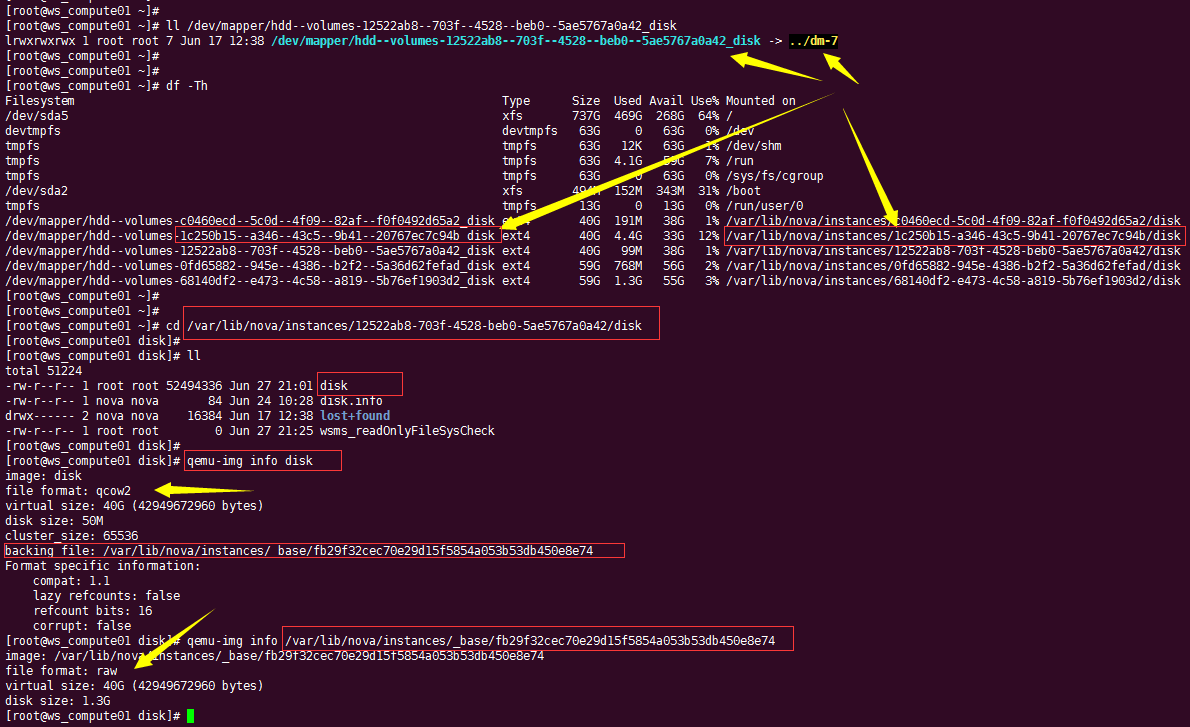
其他都好理解,这个qcow2的类型,有一点点的不一样。
他是先创建一个在LVM存储池中,创建一个LV。
然后为这个LV,创建一个软连接,通过 df -Th 可以看到 这个LV 挂载到
一个目录下。这个目录下有一个名为 disk 的qcow2文件,而这个qcow2
文件的backing file 是指向一个 base 镜像文件(raw格式)。
8.5.16 独立磁盘与LVM¶
独立磁盘
优点:虚拟机磁盘互不影响,IO不共享,不会因为一块物理盘挂了而影响所有的虚拟机。
缺点:无法像 LVM 存储池那样,做到精准而灵活的资源分配,有可能造成资源浪费或资源不足。
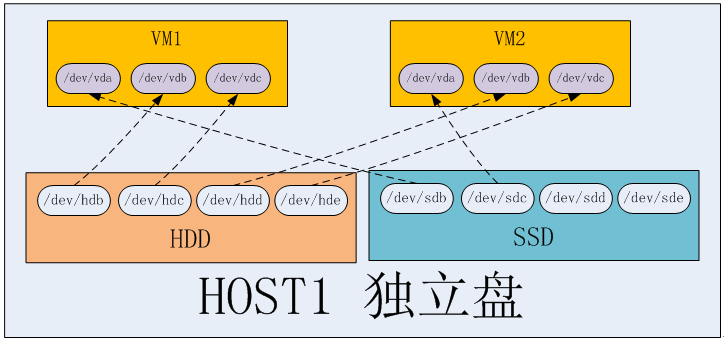
LVM
优点:可以根据业务或者其他条件(如介质类型),对多块物理盘组合成一个VG,实现精准而灵活的资源分配
缺点:不同虚拟机之间,磁盘IO共享,不同客户之间的性能会出现争抢的情况;稳定性不好,如果一块盘坏了,有可能有多个虚拟机受到影响。
8.5.17 主机组的使用¶
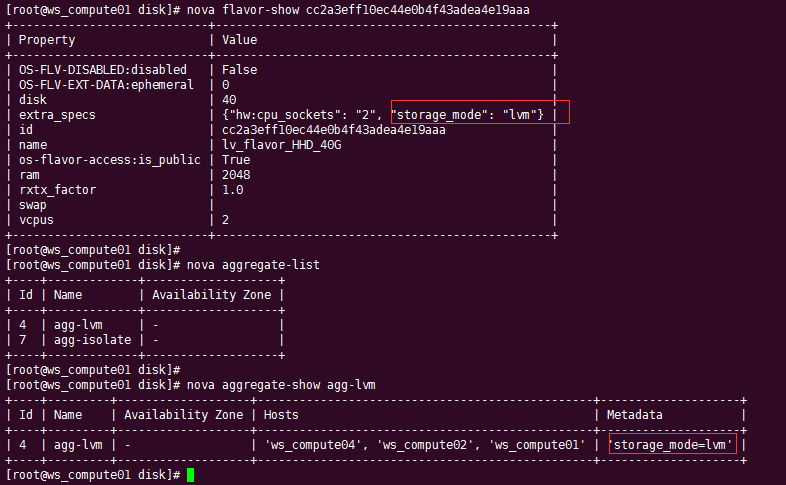
在 flavor 上有一个 extra_spec 可以设置多个参数,nova 本身自带了许多,当然这个参数可以自定义。
这个参数有什么用呢,需要搭配主机组使用。
只要在主机组上设置的metadata 的 key-value 和 extra_spec 的key-value一样就可以实现宿主机的过滤。
8.5.18 生成config drive¶
network_metadata
inst_md.ip_info
# {'fixed_ip6s': [u'2001:1001::3'], 'fixed_ips': [], 'floating_ips': []}

1562565550118¶
8.5.19 修改nova-api的接口¶
nova api 的接口参数是在 nova/api/openstack/compute/schemas/ 目录下,如创建虚拟机的接口如下:
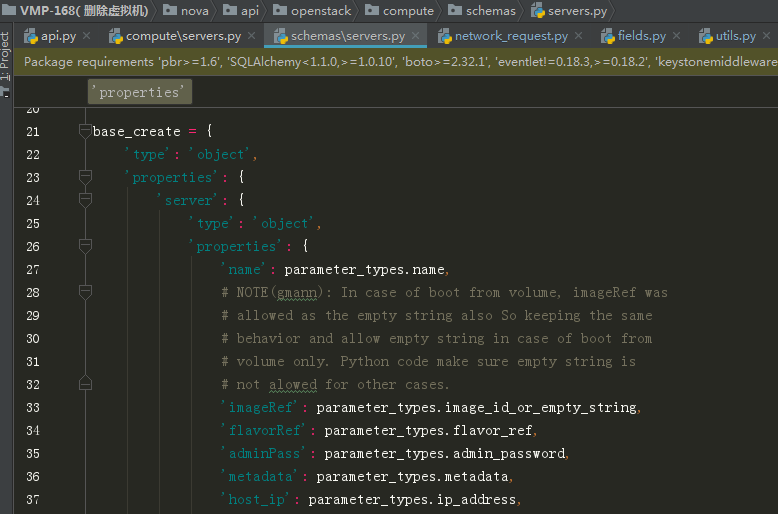
这些参数字段后面的类型是用来做参数类型的校验的。
在application 函数的头部,可以发现有如下这几种装饰器,
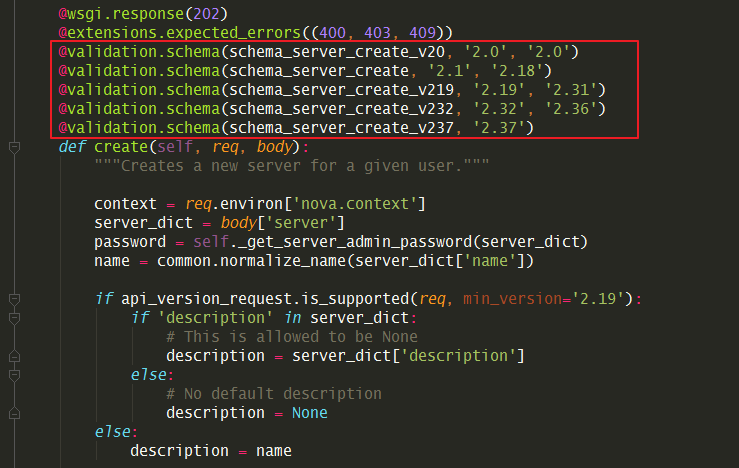
装饰器里会传入一个参数,就是 schema 的内容,通过它可以约束一个请求内的参数合法性。
schemas 的文件都统一放在 nova\api\openstack\compute\schemas 目录下。
对于创建虚拟机来说,它的 schemas 文件是在上面目录下的 servers.py
但并不是说,创建虚拟机的所有参数校验规则只在这里,nova 这边引入了 stevedore,它是 oslo 项目中为OpenStack其他项目提供动态加载功能的公共组件库(详细可以看这篇文章:https://blog.csdn.net/bill_xiang_/article/details/78852717)。通过它可以用添加扩展的方式,给 servers 更新 schemas。

关键在于这个 map 函数,它会循环所有的扩展()
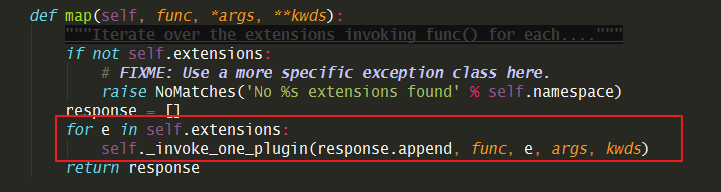
将调用传进去的 self._create_extension_schema 将已加载到的扩展schemas
更新到主schemas里去。
# [ext.obj.name for ext in self.create_schema_manager.extensions]
['MultipleCreate', 'BlockDeviceMapping', 'BlockDeviceMappingV1', 'AvailabilityZone', 'UserData', 'Keypairs', 'SchedulerHints', 'SecurityGroups', 'ConfigDrive']
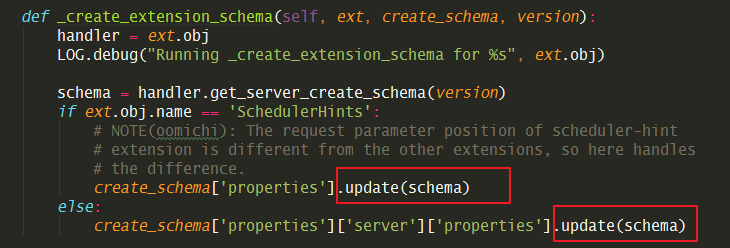
装饰器 schemas 的定义如下:
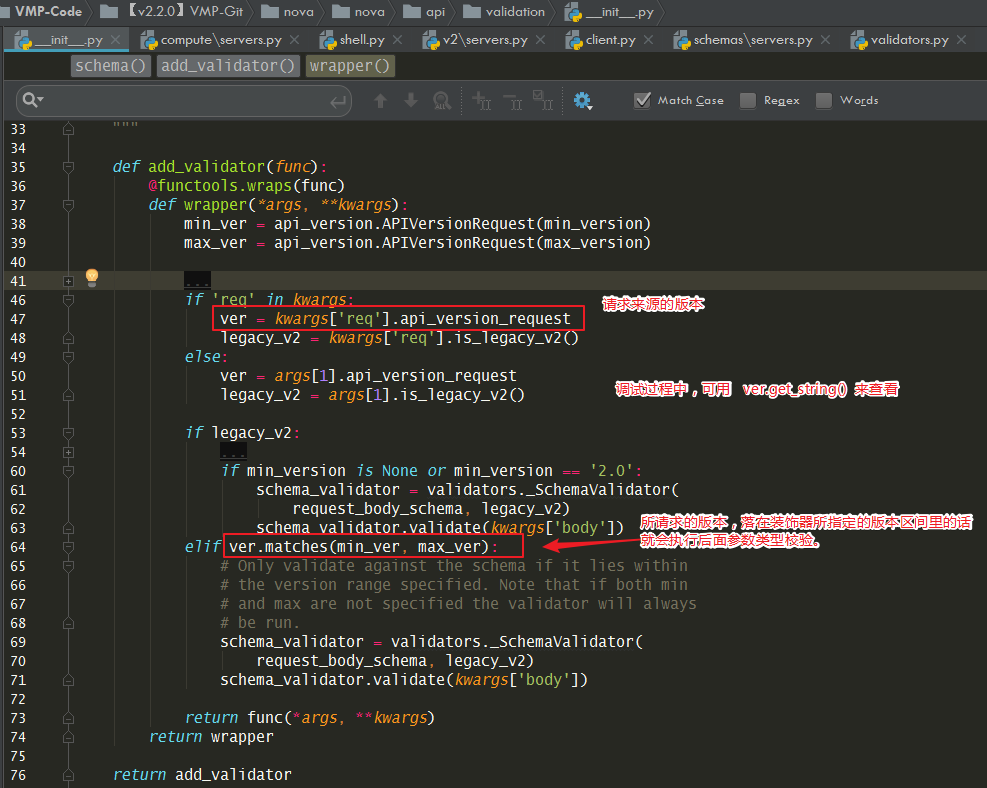
比如我们使用的 novaclient 发出的请求,是 v2.3.7的,所以 create() 顶部的五个schema 装饰器,上面四个都会空跑,不会进行校验,只有最后一个才会进入检验逻辑。
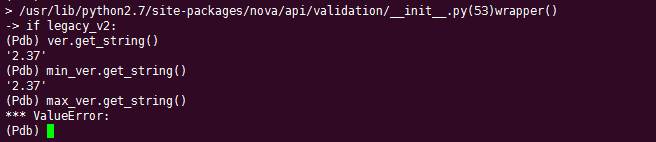
是不是很呐闷,为什么创建server 的接口,会知道关联上面那9个 schemas,其实那各自代表一种资源,属于扩展资源(它们的中心是核心资源)。
那这些扩展资源是如何关联到核心资源的,这是在哪定义的呢?
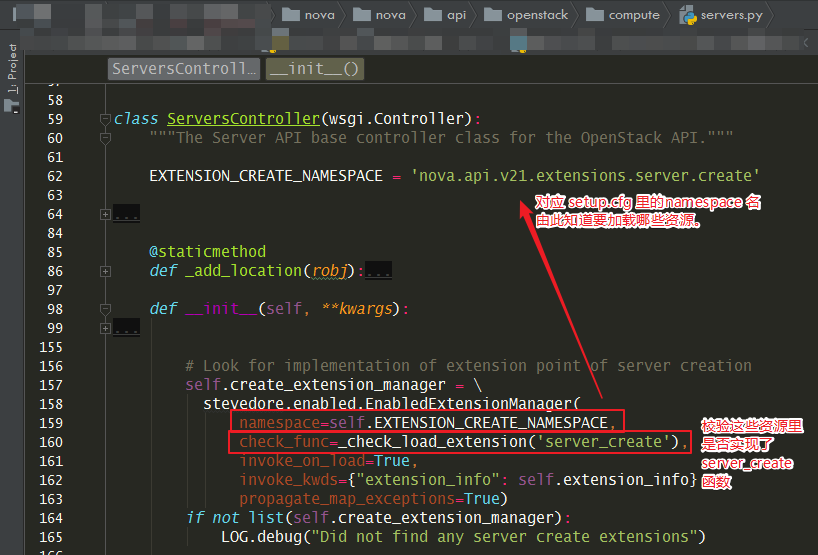
其实就是 nova 的 setup.cfg 里定义好的。
就像下面指明了 server 的 create 接口会去加载这9个扩展资源。
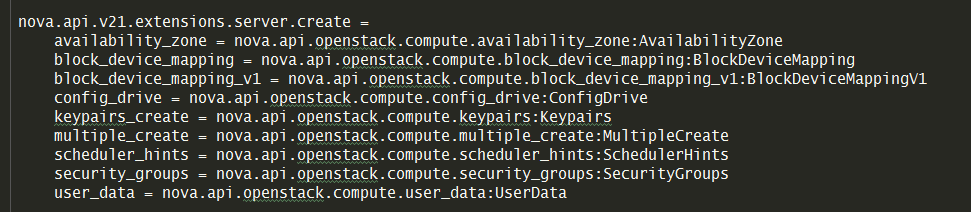
搜索一下 server_create 方法
还真的只有这 9 个资源里才会定义。
这就神奇了,servers 这个核心资源是如何加载到这些资源的,看了下代码是使用
stevedore 这个模块去动态加载,然后还会校验这些资源是否都有
server_create ,只有有这个函数,才会被正常加载进来。
8.5.20 往数据库中加字段¶
先先定义好migrate 文件
from sqlalchemy import MetaData, Text, Table, Column
def upgrade(migrate_engine):
meta = MetaData(bind=migrate_engine)
instances = Table('instances', meta, autoload=True)
if not hasattr(instances.c, 'host_routes'):
instances.create_column(Column('host_routes', Text(), default=[]))
然后在 nova/objects/instances.py 中的fields加入相应的字段。
然后在 nova/db/sqlalchemy/models.py 也要加相应的 Column
最后再执行这个命令,同步数据库
nova-manage db sync
8.5.21 如何加action¶
self._record_action_start(context, instance, instance_actions.REBOOT)
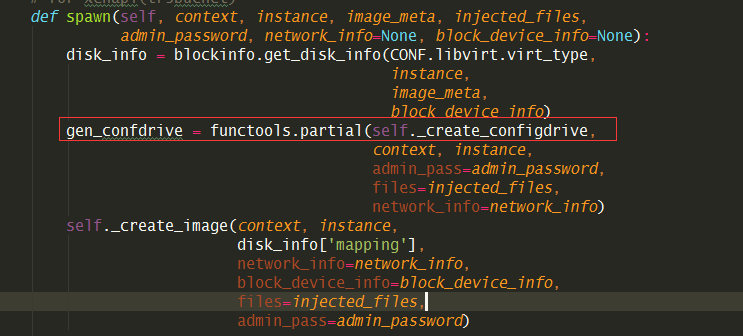
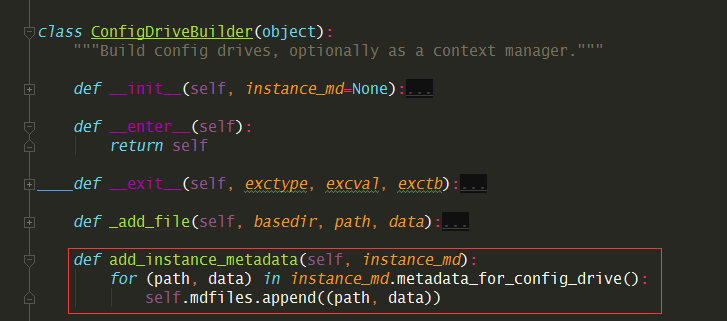
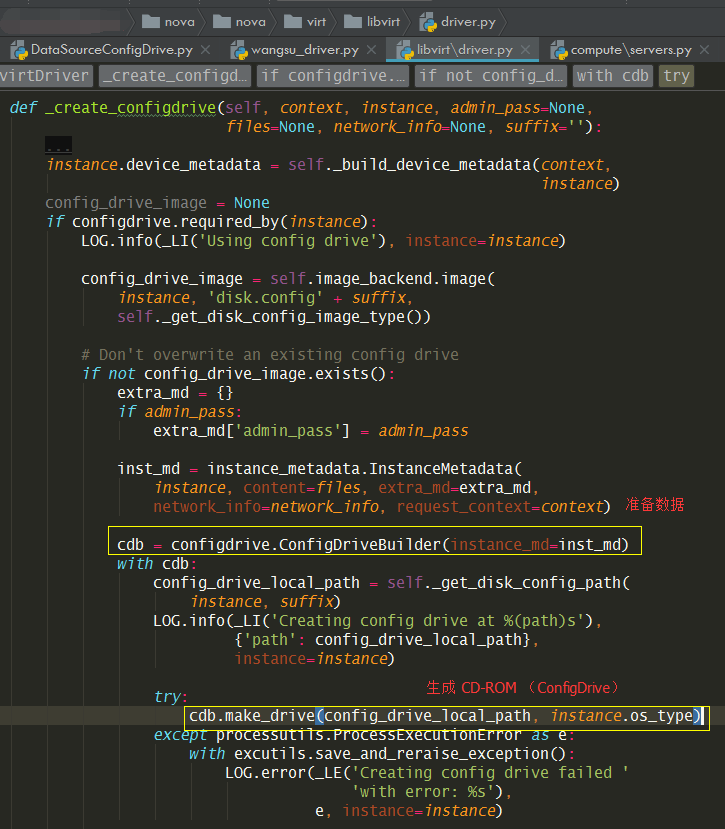
8.5.22 如何生成ConfigDrive¶
8.5.23 创建时修改虚拟机密码¶
使用下面这条命令,输入你要的密码,可以生成一串加密过字符,将这串字符传cloudinit,原封不动地放入 /etc/shadow 就可以实现密码设置。
python -c 'import crypt,getpass;pw=getpass.getpass();print(crypt.crypt(pw,crypt.METHOD_SHA512) if (pw==getpass.getpass("Confirm: ")) else exit())'
