7.5 Docker:网络通信¶

7.5.1 三种local网络¶
在docker安装的时候会自动创建三种网络可供使用。
$ docker network ls
1.【none】 :没有网络,与外界完全隔离。这个只能用在容器业务不需要联网,不需要集群,而只在本机运行业务时使用。目的就是隔绝网络。
--> 指定: $ docker run -it --network=none busybox
2. 【host】 :使用 host 网络,容器的网络配置和 host 完全一样。
--> 指定: $ docker run -it --network=host busybox
3. 【bridge】: docker安装的时候默认会创建一个 “docker0” 的linux bridge,若不指定网络,就会都挂在这个网桥下。若宿主机可上网,用这个网络创建的容器也可以上网。
--> 1. 无需指定,就使用这个网络
2. $ docker run -it --network=bridge busybox
查看网桥的信息,,可以看到有哪些容器挂在这个网桥下面
$ docker network inspect bridge
说明一下,host 网络: 直接使用 Docker host 的网络最大的好处就是性能,如果容器对网络传输效率有较高要求,则可以选择 host 网络。当然不便之处就是牺牲一些灵活性,比如要考虑端口冲突问题,Docker host 上已经使用的端口就不能再用了。
7.5.2 自定义网络¶
7.5.2.1 跨主机网络¶
上面几种网络都是自带的,同时我们也可以自定义网络(通常是网桥)。
# 指定driver=bridge
$ docker network create --driver bridge my_net1
# 如果不指定网络段,会自己生成 172.x.0.1/16 ,x 从17开始,每创建一个递增。
$ docker network create --driver bridge --subnet 192.168.7.0/24 --gatewat 192.168.7.1 my_net2
$
同一网络(网桥)下的容器,可以通信
不同网络(网桥)下的容器,docker 默认不允许通信(当然可以通过路由转发来实现),可以用命令将容器挂到另一网桥上
特别说明:
不指定subnet创建的网络,在创建容器时无法指定ip创建,会报如下错误
docker: Error response from daemon: user specified IP address is supported only when connecting to networks with user configured subnets.
命令:docker network connect my_net2
上面 7.5.1节 里的三种网络,不管是 none , host, bridge
都是 local 类型的网络,它们仅能在本机上进行通信。
而如果如实现集群通信,这三种基础的local网络是不能满足要求的。这就需要我们使用自定义网络。自定义网络,同样也分为三种(主要是根据
driver 不同):
bridge
overlay
macvlan
2.2 bridge¶
先来看看 bridge的。
# 创建网络:bridge
$ docker network create --driver bridge my_net
$ docker network create --driver bridge --subnet 192.168.7.0/24 --gatewat 192.168.7.1 my_net2
# 该网络没有指定子网,使用的是dhcp分配ip
$ docker run -it --network my_net1 <image>
# 该网络创建时有指定子网,所以可以指定ip创建
$ docker run -it --network my_net2 --ip 192.168.7.10 <image>
2.3 overlay¶
为支持容器跨主机通信,Docker 提供了 overlay driver,使用户可以创建基于 VxLAN 的 overlay 网络。
Docerk overlay 网络需要一个 key-value 数据库用于保存网络状态信息,包括 Network、Endpoint、IP 等。Consul、Etcd 和 ZooKeeper 都是 Docker 支持的 key-vlaue 软件,我们这里使用 Consul。
注:Consul 模式,不能与 swarm 模式共存,只能选取一个。
先确保,当前集群没有处在swarm模式下,如果有要先清除。
# worker 节点
$ docker swarm leave
# manager 节点
$ docker swarm leave --force
# 如果 docker node ls 还有节点存在,就删除
$ docker node rm [node_name]
然后在管理节点上创建 consul
存放网络数据,这样在一台上创建的网络都能同步到其他机器上。
# 在 docker 管理机器上运行
$ docker run -d -p 8500:8500 -h consul --name consul progrium/consul -server -bootstrap
然后到其他两台节点上,修改配置,路径为:/etc/systemd/system/docker.service.d/10-machine.conf
# 这里的 eth1 是可以和 192.168.2.55 通信的网卡
--cluster-store=consul://192.168.2.55:8500 --cluster-advertise=eth1:2376

然后重启
systemctl daemon-reload # 刷新配置,不然修改的配置不会生效
systemctl restart docker.service
在浏览器上输入地址 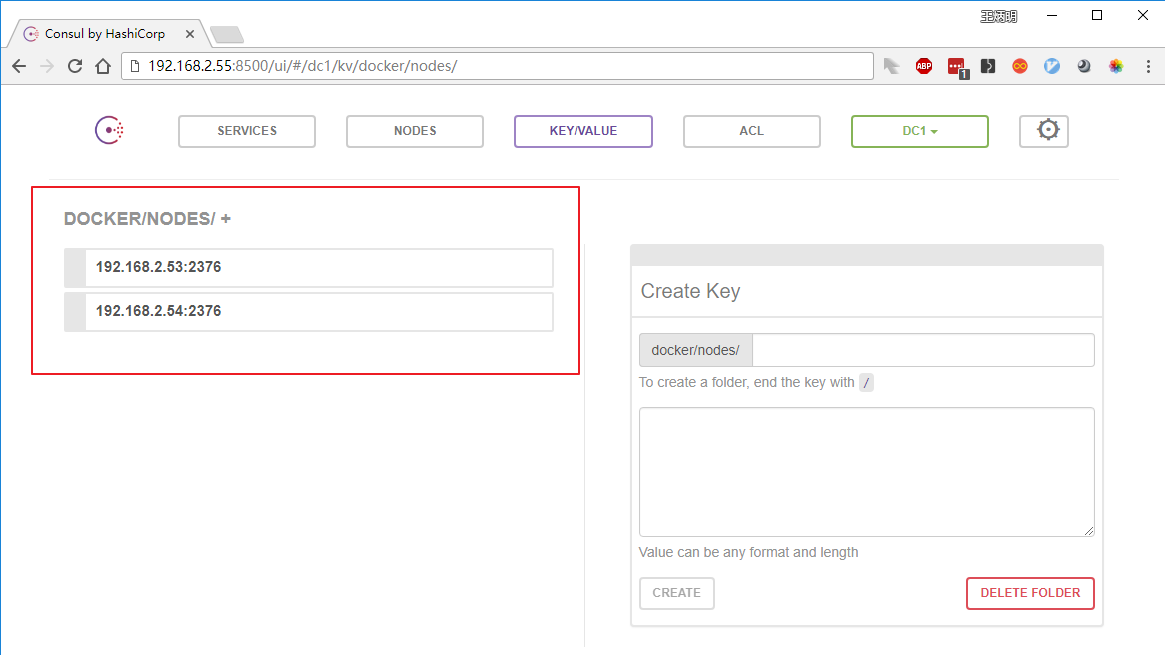
至此,Consul 安装成功。
然后就可以创建 overlay 网络了,这个网络,在没有配好 Consul
的情况下,或者没有 Swarm
的情况下是无法创建的。所以我们加入了Consul的节点上创建。
我们在 bm-docker-01 上创建
docker network create --driver overlay ov_net1
然后在 bm-docker-02 上也可以看到这个网络,原因是这些数据已经经过
Consul 进行同步了。
这个时候,我们基于这个 overlay 网络分别在两台节点上创建容器。
# bm-docker-01
docker run -itd --name bbox1 --network ov_net1 busybox
# bm-docker-02
docker run -itd --name bbox2 --network ov_net1 busybox
试着ping一下在两台 host 上的网络是否可通 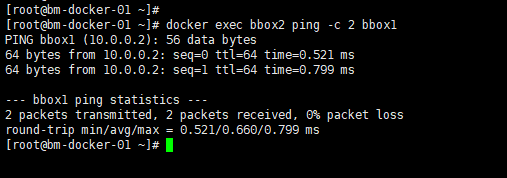
查看一下ip网卡信息。
docker exec bbox2 ip r

会发现使用 overlay 网络会有两张网卡。这是为什么呢?
原来 docker 会为每个 overlay 网络创建一个独立的
network namespace,其中会有一个
linux bridge br0,endpoint 还是由 veth pair
实现,一端连接到容器中(即 eth0),另一端连接到 namespace 的
br0 上。
br0 除了连接所有的 endpoint,还会连接一个 vxlan
设备,用于与其他 host 建立
vxlan tunnel。容器之间的数据就是通过这个 tunnel 通信的。
7.5.3 容器之间通信¶
同一网络(网桥)下的容器,可以通信
不同网络(网桥)下的容器,docker 默认不允许通信(当然可以通过路由转发来实现),可以通过在容器挂一个和另一容器在同一网桥下的网卡 命令:
docker network connect my_net2 <container id>共享网络 两个容器是可以共享一个网络的。共享网卡和配置信息。 命令:
docker run -it --network:container:<container name> busy
检测容器间的通信,都是用 ping ip 来判断的。 在我们不知道其他容器的ip时,其实是可以通过 ping 容器名,前提是这些容器都处于自定义的网络中,必须是自定义的。
如:现有两个容器,bbox1和bbox2,都用的my_net2,在bbox1里可以通过 ping bbox2来与bbox2通信。 但若现有bbox3,是使用bridge的网络,则无法使用这样的方式
7.5.4 容器与外部通信¶
包括 容器访问外部和外部访问容器。
容器访问外部 是通过 NAT 网络地址转换,来使用host的ip给外部发送数据包。 这个只要配置下iptales就可以。
外部访问容器 容器对外暴露一个端口,这个port和host的port,要映射起来,这个是由docker proxy来做的。docker proxy会时时监控host的端口,若有请求访问这个host port就重定向给容器的port
命令:docker run -it -p 8080:80 httpd
是将 host 的8080映射给httpd容器的80端口。
7.5.5 容器的通信原理¶
Docker 的网络是基于 namespace 和 cgroup 实现的。
这里来讲讲的 namespace。
在Linux下,我们一般用ip命令创建 Network Namespace,而在Docker的源码中,它并没有用ip命令,而是自己实现了ip命令内的一些功能——是用了Raw Socket发些“奇怪”的数据。
这里,我通过 ip命令的演示来重现这个过程。
## 首先,我们先增加一个网桥lxcbr0,模仿docker0
brctl addbr lxcbr0
brctl stp lxcbr0 off
ifconfig lxcbr0 192.168.10.1/24 up #为网桥设置IP地址
## 接下来,我们要创建一个network namespace - ns1
# 增加一个namesapce 命令为 ns1 (使用ip netns add命令)
ip netns add ns1
# 激活namespace中的loopback,即127.0.0.1(使用ip netns exec ns1来操作ns1中的命令)
ip netns exec ns1 ip link set dev lo up
## 然后,我们需要增加一对虚拟网卡
# 增加一个pair虚拟网卡,注意其中的veth类型,其中一个网卡要按进容器中
ip link add veth-ns1 type veth peer name lxcbr0.1
# 把 veth-ns1 按到namespace ns1中,这样容器中就会有一个新的网卡了
ip link set veth-ns1 netns ns1
# 把容器里的 veth-ns1改名为 eth0 (容器外会冲突,容器内就不会了)
ip netns exec ns1 ip link set dev veth-ns1 name eth0
# 为容器中的网卡分配一个IP地址,并激活它
ip netns exec ns1 ifconfig eth0 192.168.10.11/24 up
# 上面我们把veth-ns1这个网卡按到了容器中,然后我们要把lxcbr0.1添加上网桥上
brctl addif lxcbr0 lxcbr0.1
# 为容器增加一个路由规则,让容器可以访问外面的网络
ip netns exec ns1 ip route add default via 192.168.10.1
# 在/etc/netns下创建network namespce名称为ns1的目录,
# 然后为这个namespace设置resolv.conf,这样,容器内就可以访问域名了
mkdir -p /etc/netns/ns1
echo "nameserver 8.8.8.8" > /etc/netns/ns1/resolv.conf
上面基本上就是docker网络的原理了,只不过,
Docker的resolv.conf没有用这样的方式,而是用了上篇中的Mount Namesapce的那种方式
另外,docker是用进程的PID来做Network Namespace的名称的。
了解了这些后,你甚至可以为正在运行的docker容器增加一个新的网卡:
`ip link add peerA ``type` `veth peer name peerB ``brctl addif docker0 peerA ``ip link ``set` `peerA up ``ip link ``set` `peerB netns ${container-pid} ``ip netns ``exec` `${container-pid} ip link ``set` `dev peerB name eth1 ``ip netns ``exec` `${container-pid} ip link ``set` `eth1 up ; ``ip netns ``exec` `${container-pid} ip addr add ${ROUTEABLE_IP} dev eth1 ;`
上面的示例是我们为正在运行的docker容器,增加一个eth1的网卡,并给了一个静态的可被外部访问到的IP地址。
这个需要把外部的“物理网卡”配置成混杂模式,这样这个eth1网卡就会向外通过ARP协议发送自己的Mac地址,然后外部的交换机就会把到这个IP地址的包转到“物理网卡”上,因为是混杂模式,所以eth1就能收到相关的数据,一看,是自己的,那么就收到。这样,Docker容器的网络就和外部通了。
当然,无论是Docker的NAT方式,还是混杂模式都会有性能上的问题,NAT不用说了,存在一个转发的开销,混杂模式呢,网卡上收到的负载都会完全交给所有的虚拟网卡上,于是就算一个网卡上没有数据,但也会被其它网卡上的数据所影响。
这两种方式都不够完美,我们知道,真正解决这种网络问题需要使用VLAN技术,于是Google的同学们为Linux内核实现了一个IPVLAN的驱动,这基本上就是为Docker量身定制的。
